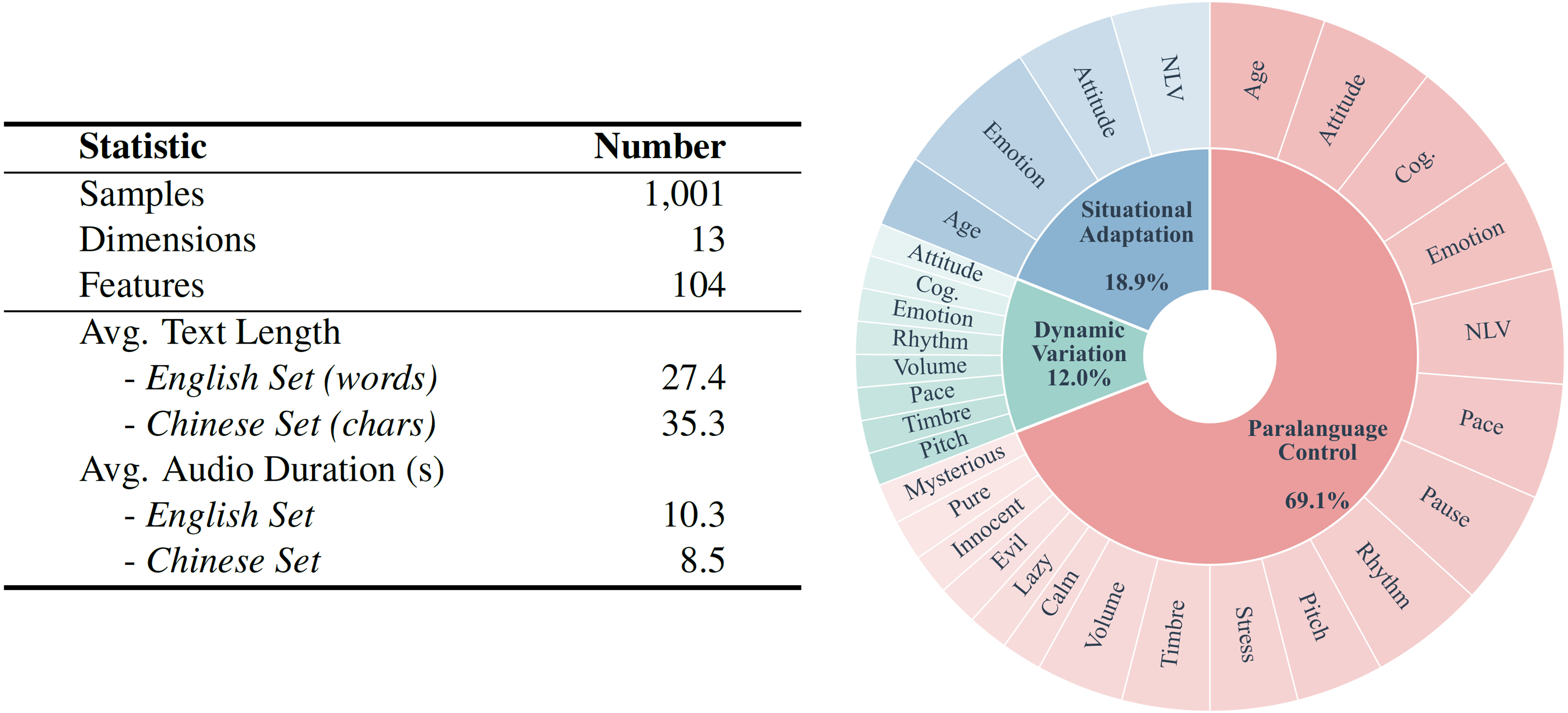
Normalized scores (0-100) on the Chinese subset ![]() SpeechParaling-Bench.
SpeechParaling-Bench.
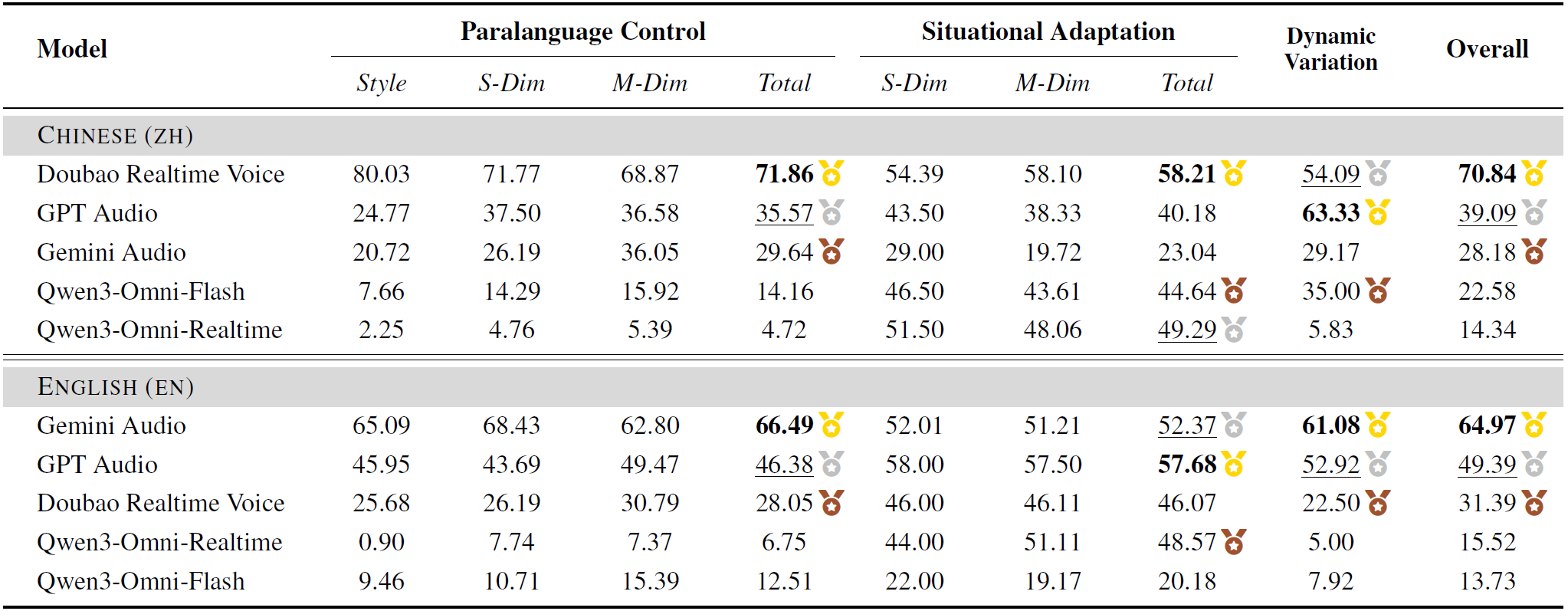
| # | Model | Date | Overall | Paralanguage Control | Dynamic Variation | Situational Adaptation |
| 1 | Doubao Realtime* 🥇 | 2025-12-20 | 70.84 | 71.86 | 54.09 | 58.21 |
| 2 | GPT Audio 🥈 | 2025-12-20 | 39.09 | 35.57 | 63.33 | 40.18 | 3 | Gemini Audio 🥉 | 2025-12-20 | 28.18 | 29.64 | 29.17 | 23.04 |
| 4 | Qwen3-Omni-Flash | 2026-01-01 | 22.58 | 14.16 | 35.00 | 44.64 |
| 5 | Qwen3-Omni-Realtime | 2026-01-12 | 14.34 | 4.72 | 5.83 | 49.29 |
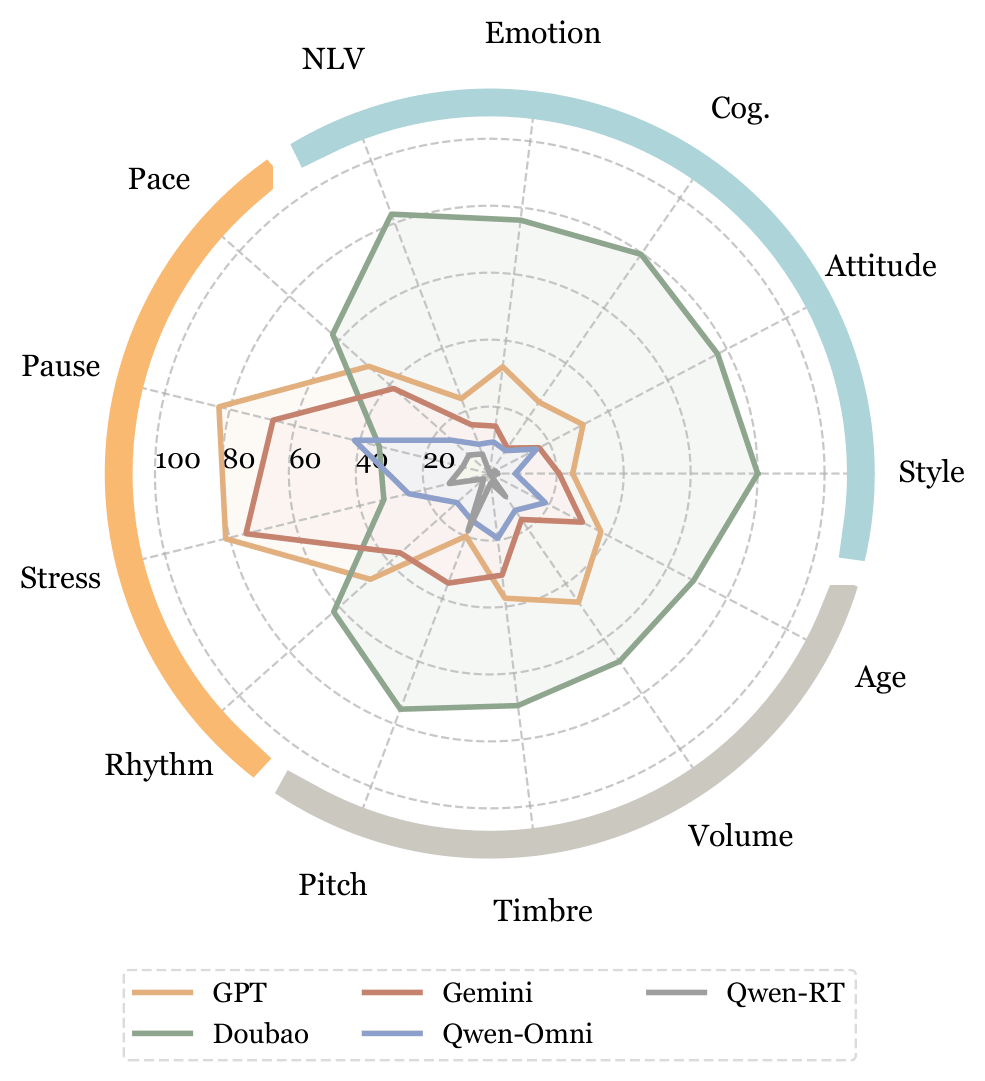
Leaderboard (English)
Normalized scores (0-100) on the English subset of ![]() SpeechParaling-Bench.
SpeechParaling-Bench.
| # | Model | Date | Overall | Paralanguage Control | Dynamic Variation | Situational Adaptation |
| 1 | Gemini Audio* 🥇 | 2025-12-20 | 64.97 | 66.49 | 61.08 | 52.37 |
| 2 | GPT Audio 🥈 | 2025-12-20 | 49.39 | 46.38 | 52.92 | 57.68 | 3 | Doubao Realtime 🥉 | 2025-12-20 | 31.39 | 28.05 | 22.50 | 46.07 |
| 4 | Qwen3-Omni-Realtime | 2026-01-01 | 15.52 | 6.75 | 5.00 | 48.57 |
| 5 | Qwen3-Omni-Flash | 2026-01-12 | 13.73 | 12.51 | 7.92 | 20.18 |
🚨 To submit your results to the leaderboard, please send to this email with your result files.
🚨 For more evaluation details, please refer to this link.